

https://whxogus215.tistory.com/134
EC2가 자꾸 죽네...? [커넥션 풀 트러블 슈팅 - 1]
서비스 오픈을 앞두고 있는 시점에서 서버가 터지는 일이 발생했는데, 한달 동안 두 번이나 이런 문제가 발생했다. 도대체 어디서 문제가 발생한건지 싶어 EC2에서 실행중인 스프링부트(WAS) 컨
whxogus215.tistory.com
지난 포스팅에서 서비스를 정식 오픈하지 않았음에도 커넥션 풀의 스레드 기아 현상으로 인해 서버가 두 번이나 죽는 문제가 발생했다. 필자는 먼저 우리 서비스의 구조인 3-Tier에서 가장 앞 단에 있는 웹서버, NginX의 로그를 확인해보았다.
1. 충격적인 NginX의 로그

NginX의 로그는 Ubuntu 기준, /var/log/nginx/access.log에 저장되어 있다.
우선 우리의 도메인을 어떻게 알아냈는지, 이 주소로 무작위 요청을 보낸 로그가 잔뜩 있었다. 로그에 찍힌 키워드로 검색한 결과, 보통 서버를 배포했을 때, 이런식으로 해외에서 한 놈만 걸리라는 식으로 브루트 포스 공격을 하는 경우가 있다고 한다. 이를 해결하기 위해 AWS의 CDN을 활용하거나 다른 리소스를 활용하는 방식도 있다고 하는데, NginX 자체에서도 걸러낼 수 있는 방법이 없을까 싶었다.
NGINX를 사용해 해외 IP 차단하기(서버 보안)
게임 개발 프로젝트를 하면서 나만의 서버를 구축해서 배포했었습니다. 그런데 로그를 확인해보니 해킹 시도가 확인되었습니다. 이런 해킹을 조금이라도 예방하기 위해 해외 IP를 차단하는 방
velog.io
https://velog.io/@c1typ0p/Nginx-GeoIP-%ED%95%B4%EC%99%B8-IP-%EC%B0%A8%EB%8B%A8%ED%95%98%EA%B8%B0
Nginx GeoIP 해외 IP 차단하기
가련한 내서버 지키기
velog.io
다행히 관련된 레퍼런스가 많았기에 충분히 해결할 수 있는 문제라고 생각했다. 하지만, 이는 커넥션풀의 에러와는 관련성이 떨어진다고 생각했다. 그 이유는 위 로그 사진에서도 알 수 있듯이, 대부분 /(루트 경로)의 GET 요청에서만 200번대를 반환할 뿐, 그 외의 요청에 대해서는 다 400번대를 응답하며 WAS에 접근하지 못하고 있다.
컨테이너로 실행 중인 WAS의 로그를 확인해 보아도 앞서 언급한 브루트 포스 공격에 의해 올바르지 않은 경로에 대한 로그들이 남아있음을 알 수 있다. 즉, 실제 서비스를 호출하는 요청은 존재하지 않았으며, 요청을 처리하는 스레드들이 커넥션을 사용하지 않았다는걸 알 수 있다.
(물론, 운영 서버에 정교한 로깅 처리가 되어 있지 않기 때문에 각각의 요청이 서비스 호출을 하였는지를 당장은 알 수 없다. 이 또한 추후 로깅 처리할 때 요구사항으로 남겨놔야 할 것 같다.)
따라서 실제 커넥션을 호출하는 로직 상에서 무슨 문제가 있을 거라는 생각을 하였고, 각종 디버그 옵션을 활성화 하여 문제를 해결하기로 하였다.
2. 디버그 옵션을 사용하여 트랜잭션 및 SQL 호출 확인
필자가 설정한 디버그 옵션은 다음과 같다. (properties 파일 기준)
logging.level.org.springframework.transaction.interceptor=TRACE
logging.level.org.springframework.orm.jpa.JpaTransactionManager=DEBUG
spring.jpa.properties.hibernate.show_sql=true
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.properties.hibernate.use_sql_comments=true
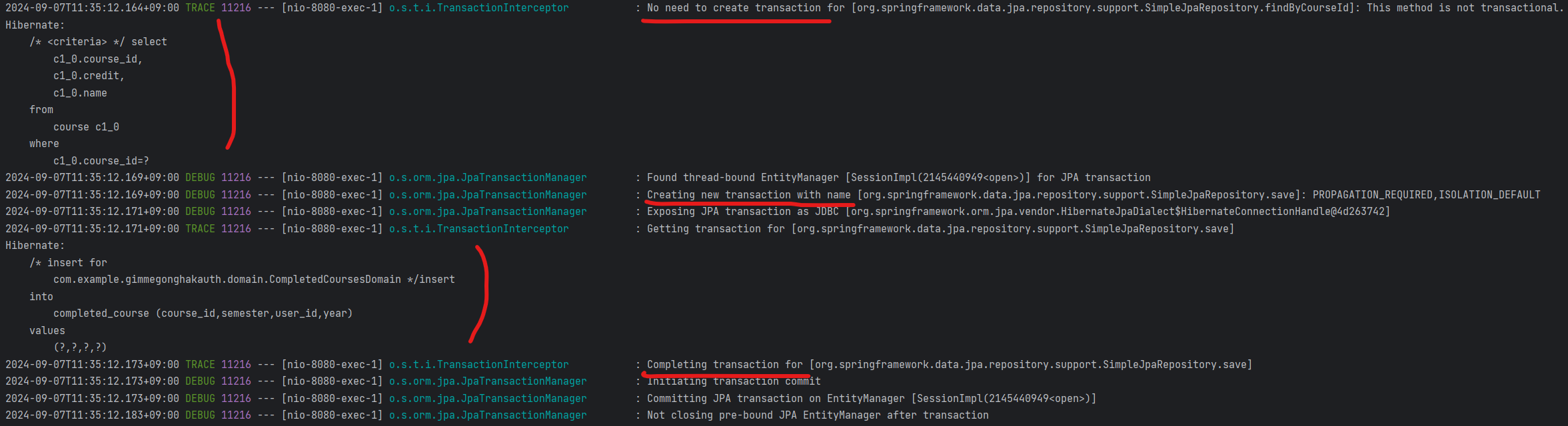
logging 레벨 설정을 통해 실제 트랜잭션이 생성되는지 아니면 생성되지 않고 기존 트랜잭션에 참여하는지
엔티티 매니저는 다시 생성되는지 등을 알 수 있다.
hibernate 옵션은 실제 hibarnate가 실행하는 쿼리를 확인할 수 있게 한다.
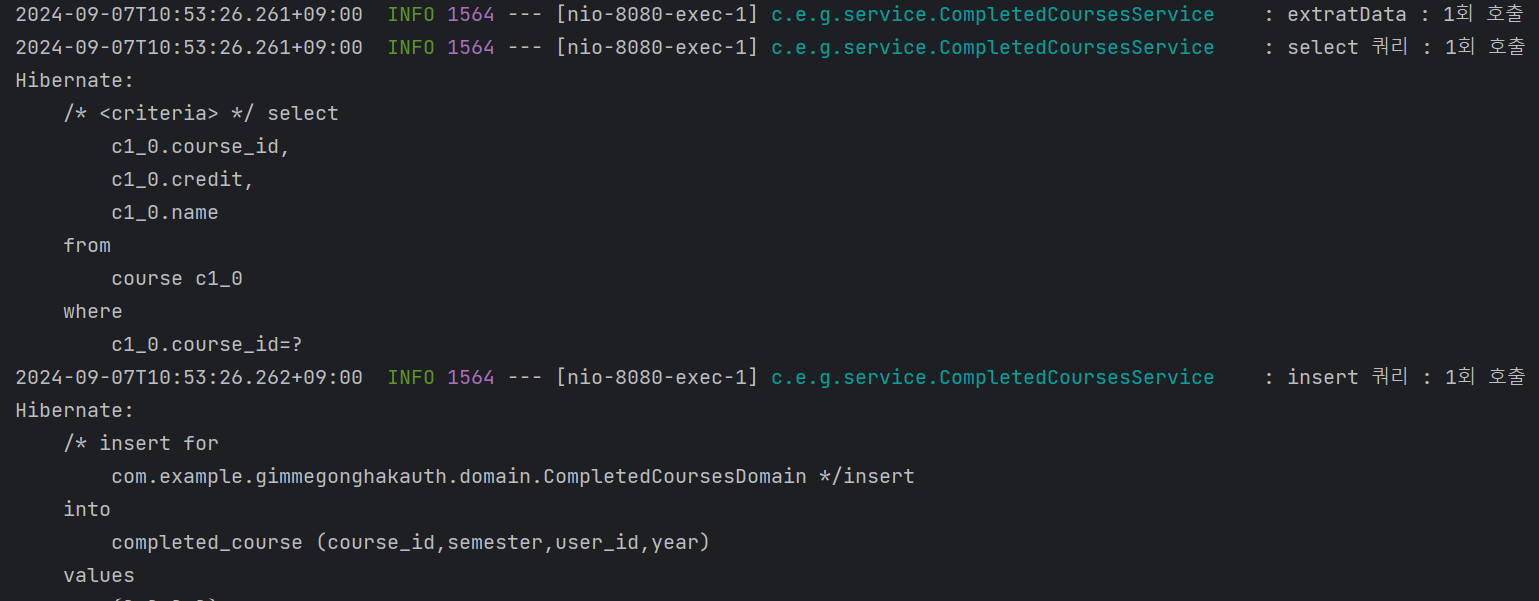
이 옵션 덕분에 필자는 트랜잭션을 실행하고, 데이터를 저장하는 save가 호출되는 로직에서의 문제점을 확인할 수 있었다.

extractData라는 메서드는 전달받은 엑셀파일의 각 Row 값을 클래스로 생성하여 영속성 컨텍스트에 저장하는 역할을 한다. 이 때, 연관관계가 있는 엔티티를 호출하기 위해 find~ 메서드가 한 번, 저장하기 위해 save 메서드가 한 번씩 호출된다.
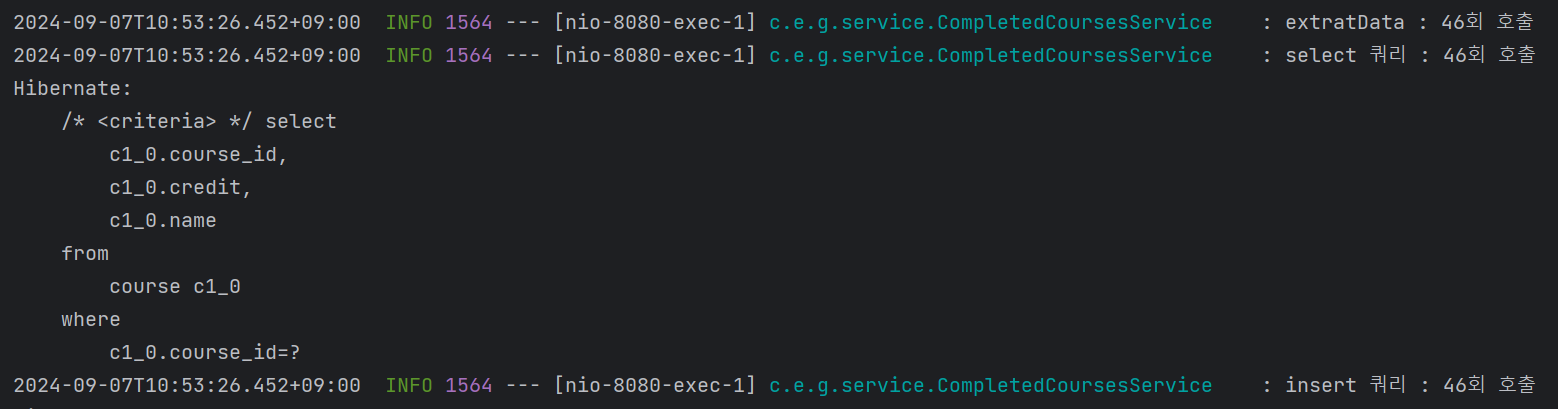
즉, 하나의 Row 당 select와 insert가 1개씩 생성되며, Row가 50개가 넘어간다면 생성되는 쿼리는 100개가 된다.
우리 서비스의 특성 상, 전달되는 Row의 개수는 적게는 10개 많게는 50개가 될 수도 있다. select 쿼리의 경우, 검색해야 하는 조건이 Row 마다 다를 수 있기 때문에 매번 호출을 할 수는 있는 반면에 insert 쿼리는 굳이 저렇게 까지 많이 호출될 필요가 있을까 하는 생각이 들었다.
여기서 발생할 수 있는 문제는 다음과 같았다.
- 하나의 스레드가 하나의 커넥션을 물고 있는 시간이 많아진다.
- DB에 전달하는 쿼리 수가 많아짐에 따라 I/O 횟수가 많아진다.
- 하나의 요청을 처리하기 위해 생성되는 트랜잭션 수가 불필요하게 많다. (리소스를 비효율적으로 사용)
만약, 우리 서비스가 오픈하여 동시 사용자가 많아질 경우, 모두가 데이터를 저장하는 요청을 하게 된다면 분명 DB에 큰 부하가 생길 수 있다. 따라서 생성한 객체를 List에 담아 반복문이 끝났을 때, saveAll을 호출하여 한 번에 보내는 방법을 사용하였다.
하지만 생성되는 insert 쿼리의 수는 변하지 않았다.
https://techblog.woowahan.com/2695/
MySQL 환경의 스프링부트에 하이버네이트 배치 설정해 보기 | 우아한형제들 기술블로그
안녕하세요. 배민상품시스템팀 권순규 입니다. 저희팀에서 하이버네이트 배치 설정을 통해 대량 insert/update 시의 속도개선을 경험하여 공유드리고자 합니다. 전체 예제 파일은 github 에서 확인
techblog.woowahan.com
해당 글에 따르면, JPA의 영속성 컨텍스트가 관리하는 엔티티는 식별자인 ID 값이 있어야 하는데 IDENTITY의 경우, DB에 insert를 해야만 ID를 얻어올 수 있기 때문에 batchInsert를 지원하지 않는다고 한다.
(검색 키워드 : 영속성 컨텍스트 1차 캐시)
insert 쿼리를 한 번에 모아 실행해서 성능 최적화를 기대할 수 있는 것인데, JPA를 사용한 IDENTITY의 경우, 영속화를 위한 ID를 얻기 위해 insert 쿼리를 먼저 실행해야 하므로 사실상 batch의 장점이 퇴색되기 때문이다.
따라서 JPA가 아닌 JDBC의 jdbctemplate을 활용하여 batchInsert를 적용하기로 하였다.
이에 대한 자세한 내용과 결과는 다음 포스팅에서 적도록 하겠다.
'사이드 프로젝트 > gonghak98 - 세종대 공학인증 웹 사이트' 카테고리의 다른 글
| 로그를 통해 우리는 논리적 사고를 할 수 있다 [커넥션 풀 트러블 슈팅 - 3] (4) | 2024.09.07 |
|---|---|
| EC2가 자꾸 죽네...? [커넥션 풀 트러블 슈팅 - 1] (0) | 2024.08.30 |